Sysman Programming Guide¶
Introduction¶
Sysman is the System Resource Management library used to monitor and control the power and performance of accelerator devices.
High-level overview¶
Environment Variables¶
The following environment variables are required to be enabled during initialization for the respective feature.
Category |
Name |
Values |
Description |
|---|---|---|---|
Sysman |
ZES_ENABLE_SYSMAN |
{0, 1} |
Enables driver initialization and dependencies for system management |
Sysman |
ZES_ENABLE_SYSMAN_LOW_POWER |
{0, 1} |
Driver initialize the device in low power mode |
Initialization¶
An application wishing to manage power and performance for devices first needs to use the Level0 Core API to enumerate through available accelerator devices in the system and select those of interest.
For each selected device handle, applications can cast it to a Sysman device handle to manage system resources of the device.
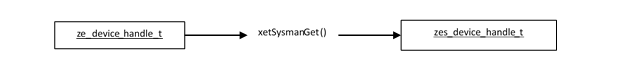
There is a unique handle for each device. Multiple threads can use the handle. If concurrent accesses are made to the same device property through the handle, the last request wins.
The pseudo code below shows how to enumerate the GPU devices in the system and create Sysman handles for them:
function main( ... )
if (zeInit(0) != ZE_RESULT_SUCCESS)
output("Can't initialize the API")
else
# Discover all the drivers
uint32_t driversCount = 0
zeDriverGet(&driversCount, nullptr)
ze_driver_handle_t* allDrivers = allocate(driversCount * sizeof(ze_driver_handle_t))
zeDriverGet(&driversCount, allDrivers)
ze_driver_handle_t hDriver = nullptr
for(i = 0 .. driversCount-1)
# Discover devices in a driver
uint32_t deviceCount = 0
zeDeviceGet(allDrivers[i], &deviceCount, nullptr)
ze_device_handle_t* allDevices =
allocate_memory(deviceCount * sizeof(ze_device_handle_t))
zeDeviceGet(allDrivers[i], &deviceCount, allDevices)
for(devIndex = 0 .. deviceCount-1)
ze_device_properties_t device_properties
zeDeviceGetProperties(allDevices[devIndex], &device_properties)
if(ZE_DEVICE_TYPE_GPU != device_properties.type)
next
# Get the Sysman device handle
zes_device_handle_t hSysmanDevice = (zes_device_handle_t)allDevices[devIndex]
# Start using hSysmanDevice to manage the device
free_memory(...)
Global device management¶
The following operations are provided to access overall device information and control aspects of the entire device:
Get device UUID, deviceID, number of sub-devices
Get Brand/model/vendor name
Query the information about processes using this device
Reset device
Query if the device has been repaired
Query if the device needs to be reset and for what reasons (wedged, initiate repair)
PCI information:
Get configured bars
Get maximum supported bandwidth
Query current speed (GEN/no. of lanes)
Query current throughput
Query packet retry counters
The full list of available functions is described below.
Device component management¶
Aside from management of the global properties of a device, there are many device components that can be managed to change the performance and/or power configuration of the device. Similar components are broken into classes and each class has a set of operations that can be performed on them.
For example, devices typically have one or more frequency domains. The Sysman API exposes a class for frequency and an enumeration of all frequency domains that can be managed.
The table below summarizes the classes that provide device queries and an example list of components that would be enumerated for a device with two sub-devices. The table shows the operations (queries) that will be provided for all components in each class.
Class |
Components |
Operations |
|---|---|---|
Card: power Package: power Sub-device 0: total power Sub-device 1: total power |
Get energy consumption |
|
Sub-device 0: GPU frequency Sub-device 0: Memory frequency Sub-device 1: GPU frequency Sub-device 1: Memory frequency |
List available frequencies Set frequency range Get frequencies Get throttle reasons Get throttle time |
|
Sub-device 0: All engines Sub-device 0: Compute engines Sub-device 0: Media engines Sub-device 0: Copy engines Sub-device 1: All engines Sub-device 1: Compute engines Sub-device 1: Media engines Sub-device 1: Copy engines |
Get busy time |
|
Sub-device 0: All engines Sub-device 1: All engines |
Get scheduler mode and properties Get scheduler mode and properties |
|
Sub-device 0: Enumerates each firmware Sub-device 1: Enumerates each firmware |
Get firmware name and version |
|
Sub-device 0: Memory module Sub-device 1: Memory module |
Get maximum supported bandwidth Get free memory Get current bandwidth |
|
Sub-device 0: Enumerates each port Sub-device 1: Enumerates each port |
Get port configuration (UP/DOWN) Get physical link details Get port health (healthy/degraded/failed/disabled) Get remote port Get port rx/tx speed Get port rx/tx bandwidth |
|
Package: temperature (min, max) Sub-device 0: GPU temperature (min, max) Sub-device 0: Memory temperature (min, max) Sub-device 1: GPU temperature (min, max) Sub-device 1: Memory temperature (min, max) |
Get current temperature sensor reading |
|
Package: Power supplies |
Get details about the power supply Query current state (temperature, current, fan) |
|
Package: Fans |
Get details (max fan speed) Get config (fixed fan speed, temperature-speed table) Query current fan speed |
|
Package: LEDs |
Get details (RGB capable) Query current state (on, color) |
|
Sub-device 0: One set of RAS error counters Sub-device 1: One set of RAS error counters |
Read RAS total correctable and uncorrectable error counters Read breakdown of errors by category (no. resets, no. programming errors, no. programming errors, no. driver errors, no. compute errors, no. cache errors, no. memory errors, no. PCI errors, no. display errors, no. non-compute errors) |
|
Package: SCAN test suite Package: ARRAY test suite |
Get list of all diagnostics tests |
The table below summarizes the classes that provide device controls and an example list of components that would be enumerated for a device with two sub-devices. The table shows the operations (controls) that will be provided for all components in each class.
Class |
Components |
Operations |
|---|---|---|
Card: power Package: power |
Set sustained power limit Set burst power limit Set peak power limit |
|
Sub-device 0: GPU frequency Sub-device 0: Memory frequency Sub-device 1: GPU frequency Sub-device 1: Memory frequency |
Set frequency range |
|
Sub-device 0: All engines Sub-device 1: All engines |
Set scheduler mode Set scheduler mode |
|
Sub-device 0: Compute Sub-device 0: Media Sub-device 1: Compute Sub-device 1: Media |
Tune workload performance |
|
Sub-device 0: Control entire sub-device Sub-device 1: Control entire sub-device |
Disable opportunistic standby standby |
|
Sub-device 0: Enumerates each firmware Sub-device 1: Enumerates each firmware |
Flash new firmware |
|
Sub-device 0: Control each port Sub-device 1: Control each port |
Configure port UP/DOWN Turn beaconing ON/OFF |
|
Package: Fans |
Set config (fixed speed, temperature- speed table) |
|
Package: LEDs |
Turn LED on/off and set color |
|
SCAN test suite ARRAY test suite |
Run all or a subset of diagnostic tests in the test suite |
Device component enumeration¶
The Sysman API provides functions to enumerate all components in a class that can be managed.
For example, there is a frequency class which is used to control the frequency of different parts of the device. On most devices, the enumerator will provide two handles, one to control the GPU frequency and one to enumerate the device memory frequency. This is illustrated in the figure below:
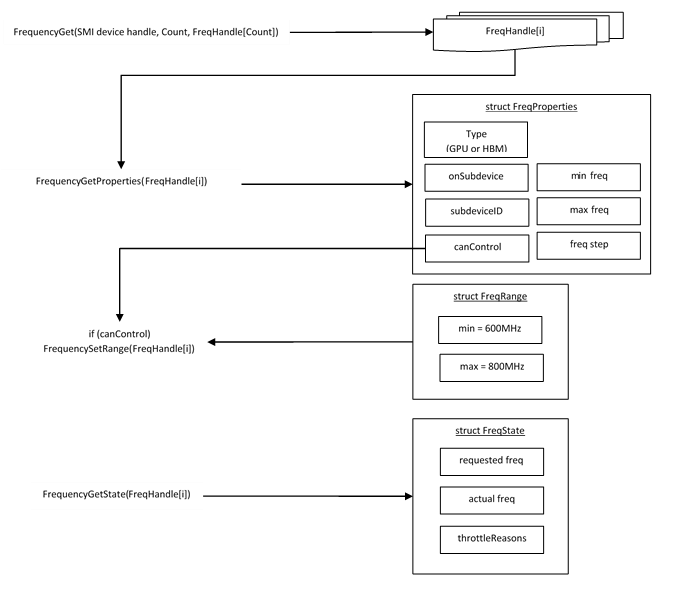
In the C API, each class is associated with a unique handle type (e.g. zes_freq_handle_t refers to a frequency component). In the C++ API, each class is a C++ class (e.g. An instance of the class zes::SysmanFrequency refers to a frequency component).
The pseudo code below shows how to use the Sysman API to enumerate all GPU frequency components and fix each to a specific frequency if this is supported:
function FixGpuFrequency(zes_device_handle_t hSysmanDevice, double FreqMHz)
uint32_t numFreqDomains
if ((zesDeviceEnumFrequencyDomains(hSysmanDevice, &numFreqDomains, NULL) == ZE_RESULT_SUCCESS))
zes_freq_handle_t* pFreqHandles =
allocate_memory(numFreqDomains * sizeof(zes_freq_handle_t))
if (zesDeviceEnumFrequencyDomains(hSysmanDevice, &numFreqDomains, pFreqHandles) == ZE_RESULT_SUCCESS)
for (index = 0 .. numFreqDomains-1)
zes_freq_properties_t props
if (zesFrequencyGetProperties(pFreqHandles[index], &props) == ZE_RESULT_SUCCESS)
# Only change the frequency of the domain if:
# 1. The domain controls a GPU accelerator
# 2. The domain frequency can be changed
if (props.type == ZES_FREQ_DOMAIN_GPU
and props.canControl)
# Fix the frequency
zes_freq_range_t range
range.min = FreqMHz
range.max = FreqMHz
zesFrequencySetRange(pFreqHandles[index], &range)
free_memory(...)
Sub-device management¶
A Sysman device handle operates at the device level. If a sub-device device handle is passed to any of the Sysman functions, the result will be as if the device handle was used.
The enumerator for device components will return a list of components that are located in each sub-device. Properties for each component will indicate in which sub-device it is located. If software wishing to manage components in only one sub-device should filter the enumerated components using the sub-device ID (see ze_device_properties_t.subdeviceId).
The figure below shows the frequency components that will be enumerated on a device with two sub-devices where each sub-device has a GPU and device memory frequency control:
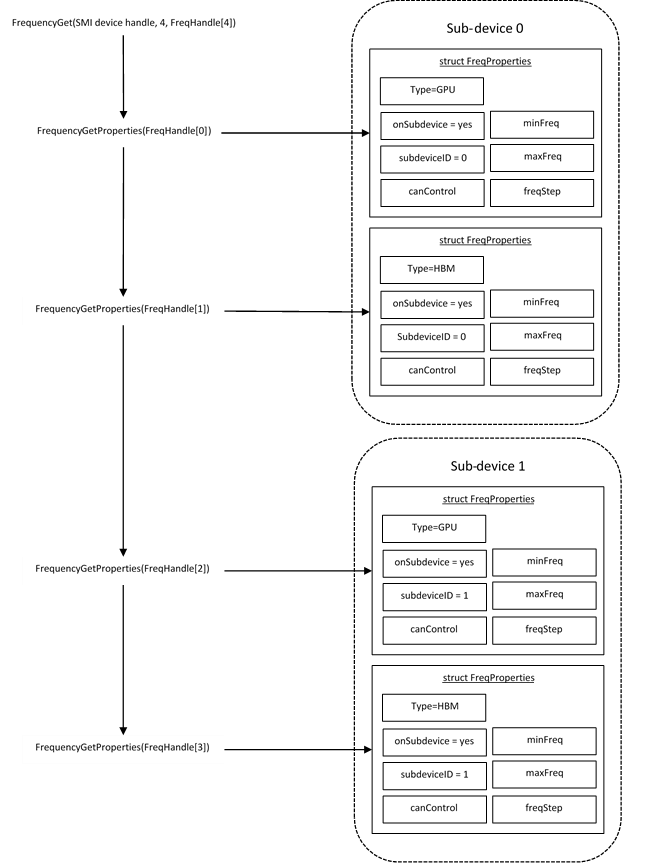
The pseudo code below shows how to fix the GPU frequency on a specific sub-device (notice the additional sub-device check):
function FixSubdeviceGpuFrequency(zes_device_handle_t hSysmanDevice, uint32_t subdeviceId, double FreqMHz)
uint32_t numFreqDomains
if ((zesDeviceEnumFrequencyDomains(hSysmanDevice, &numFreqDomains, NULL) == ZE_RESULT_SUCCESS))
zes_freq_handle_t* pFreqHandles =
allocate_memory(numFreqDomains * sizeof(zes_freq_handle_t))
if (zesDeviceEnumFrequencyDomains(hSysmanDevice, &numFreqDomains, pFreqHandles) == ZE_RESULT_SUCCESS)
for (index = 0 .. numFreqDomains-1)
zes_freq_properties_t props
if (zesFrequencyGetProperties(pFreqHandles[index], &props) == ZE_RESULT_SUCCESS)
# Only change the frequency of the domain if:
# 1. The domain controls a GPU accelerator
# 2. The domain frequency can be changed
# 3. The domain is located in the specified sub-device
if (props.type == ZES_FREQ_DOMAIN_GPU
and props.canControl
and props.subdeviceId == subdeviceId)
# Fix the frequency
zes_freq_range_t range
range.min = FreqMHz
range.max = FreqMHz
zesFrequencySetRange(pFreqHandles[index], &range)
free_memory(...)
Events¶
Events are a way to determine if changes have occurred on a device e.g. new RAS errors without polling the Sysman API. An application registers the events that it wishes to receive notification about and then it listens for notifications. The application can choose to block when listening - this will put the calling application thread to sleep until new notifications are received.
The API enables registering for events from multiple devices and listening for any events coming from any devices by using one function call.
Once notifications have occurred, the application can use the query Sysman interface functions to get more details.
The following events are provided:
Any RAS errors have occurred
The full list of available functions for handling events is described below.
Telemetry and timestamps¶
Many of the API calls return underlying hardware telemetry (counters). These counters are typically monotonic and wrap around at the their bit width boundaires. An application will typically want to take the delta between two samples. Many times, the rate of change of a counter is required. For example, sampling a counter for bytes transmitted through a link and dividing by the delta time between the samples will yield average bandwidth.
When returning telemetry, the API will include a timestamp when the underlying hardware counter was sampled. Each timestamp is only relevant to the telemetry that it accompanies. Each timestamp associated with a piece of telemetry can have it’s own absolute base that can be different from timestamps return with other telemetry. As a result, no calculation should be made based on timestamps returned from different telemetry.
The timestamps are not guaranteed to have the same base between applications. They should only be used within the execution of a single application.
Interface details¶
Global operations¶
Device Properties¶
The following operations permit getting properties about the entire device:
Function |
Description |
|---|---|
Get static device properties - device UUID, sub-device ID, device brand/model/vendor strings |
|
Determine device state: was the device repaired, does the device need to be reset and for what reasons (wedged, initiate repair) |
The pseudo code below shows how to display general information about a device:
function ShowDeviceInfo(zes_device_handle_t hSysmanDevice)
zes_device_properties_t devProps
zes_device_state_t devState
if (zesDeviceGetProperties(hSysmanDevice, &devProps) == ZE_RESULT_SUCCESS)
output(" UUID: %s", devProps.core.uuid.id)
output(" #subdevices: %u", devProps.numSubdevices)
output(" brand: %s", devProps.brandName)
output(" model: %s", devProps.modelName)
if (zesDeviceGetState(hSysmanDevice, &devState) == ZE_RESULT_SUCCESS)
output(" Was repaired: %s", (devState.repaired == ZES_REPAIR_STATUS_PERFORMED) ? "yes" : "no")
if (devState.reset != 0)
{
output("DEVICE RESET REQUIRED:")
if (devState.reset & ZES_RESET_REASON_FLAG_WEDGED)
output("- Hardware is wedged")
if (devState.reset & ZES_RESET_REASON_FLAG_REPAIR)
output("- Hardware needs to complete repairs")
}
}
Host Processes¶
The following functions provide information about host processes that are using the device:
Function |
Description |
|---|---|
Get information about all processes that are using this device - process ID, device memory allocation size, accelerators being used. |
Using the process ID, an application can determine the owner and the path to the executable - this information is not returned by the API.
Device reset¶
The device can be reset using the following function:
Function |
Description |
|---|---|
Requests that the driver perform a PCI bus reset of the device. |
PCI link operations¶
The following functions permit getting data about the PCI endpoint for the device:
Function |
Description |
|---|---|
Get static properties for the PCI port - BDF address, number of bars, maximum supported speed |
|
Get current PCI port speed (number of lanes, generation) |
|
Get information about each configured PCI bar |
|
Get PCI statistics - throughput, total packets, number of packet replays |
The pseudo code below shows how to output the PCI BDF address:
function ShowPciInfo(zes_device_handle_t hSysmanDevice)
zes_pci_properties_t pciProps;
if (zesDevicePciGetProperties(hSysmanDevice, &pciProps) == ZE_RESULT_SUCCESS)
output(" PCI address: %04u:%02u:%02u.%u",
pciProps.address.domain,
pciProps.address.bus,
pciProps.address.device,
pciProps.address.function);
Operations on power domains¶
The PSU (Power Supply Unit) provides power to a device. The amount of power drawn by a device is a function of the voltage and frequency, both of which are controlled by the Punit, a micro-controller on the device. If the voltage and frequency are too high, two conditions can occur:
Over-current - This is where the current drawn by the device exceeds the maximum current that the PSU can supply. The PSU asserts a signal when this occurs, and it is processed by the Punit.
Over-temperature - The device is generating too much heat that cannot be dissipated fast enough. The Punit monitors temperatures and reacts when the sensors show the maximum temperature exceeds the threshold TjMax (typically 100 degrees Celsius).
When either of these conditions occurs, the Punit throttles the frequencies/voltages of the device down to their minimum values, severely impacting performance. The Punit avoids such severe throttling by imposing power limits. There are two types of power limits:
Reactive - In this case, the Punit will measure the moving average over some interval of the actual power (hardware measurement). If the average power exceeds the limit, Punit will start slowly decreasing the maximum frequency limits that can be requested for each frequency domain. Conversely, if the average power is below the limit, Punit will slowly increase the maximum frequency limits that can be requested up to the hardware frequency limit for each domain. When user/driver frequency requests are above the maximum frequency limits, throttling occurs and this should normally reduce the power.
Proactive - In this case, the Punit can perform a calculation based on the current configuration of the chip and frequency requests to predict the worst case power that could be generated. If this calculation exceeds the proactive limit, a search is done to find the maximum frequency limits that will fit within the limit and those will be actual frequencies.
The table below summaries the different types of power limits that can be configured on a power domain. Note that the sustained and burst power limits are only reactive, whereas a peak power limit can be either reactive or proactive. As a general rule, card-level peak power limits are reactive whereas they are proactive for all other power domains that can be enumerated on the chip.
Limit |
Window |
Description |
|---|---|---|
Peak (proactive) |
Instantaneous |
Punit predicts the worst case power for the current frequency requests and if it exceeds the limit, the actual frequencies will be lower. This threshold is referred to as PL4 - Power Limit 4 - or peak power. |
Peak (reactive) |
100usec |
Punit tracks the 100usec moving average of power. When this exceeds a programmable threshold, the Punit starts throttling frequencies/voltages. The threshold is referred to as Psys - System Power limit. |
Burst (reactive) |
2ms |
Punit tracks the 2ms moving average of power. When this exceeds a programmable threshold, the Punit starts throttling frequencies/voltages. The threshold is referred to as PL2 - Power Limit 2 - or burst power. |
Sustained (reactive) |
28sec |
Punit tracks the 28sec moving average of power. When this exceeds a programmable threshold, the Punit throttles frequencies/voltages. The threshold is referred to as PL1 - Power Limit 1 - or sustained power. |
The default factory values are tuned assuming the device is operating at normal temperatures running significant workloads:
The peak power limit is tuned to avoid tripping the PSU over-current signal for all but the most intensive compute workloads. Most workloads should be able to run at maximum frequencies without hitting this condition.
The burst power limit permits most workloads to run at maximum frequencies for short periods.
The sustained power limit will be triggered if high frequencies are requested for lengthy periods (configurable, default is 28sec) and the frequencies will be throttled if the high requests and utilization of the device continues.
Some power domains support requesting the event ZES_EVENT_TYPE_FLAG_ENERGY_THRESHOLD_CROSSED be generated when the energy consumption exceeds some value. This can be a useful technique to suspend an application until the GPU becomes busy. The technique involves calling zesPowerSetEnergyThreshold() with some delta energy threshold, registering to receive the event using the function zesDeviceEventRegister() and then calling zesDriverEventListen() to block until the event is triggered. When the energy consumed by the power domain from the time the call is made exceeds the specified delta, the event is triggered, and the application is woken up.
A device can have multiple power domains:
One card level power domain that handles the power consumed by the entire PCIe card.
One package level power domain that handles the power consumed by the entire accelerator chip. This includes the power of all sub-devices on the chip.
One or more power domains for each sub-device if the product has sub-devices.
The following functions are provided to manage the power of the device:
Function |
Description |
|---|---|
Enumerate the power domains. |
|
Returns a handle to the card-level power domain if available/applicable. |
|
Get the minimum/maximum power limit that can be specified when changing the power limits of a specific power domain. Also read the factory default sustained power limit of the part. |
|
Read the energy consumption of the specific domain. |
|
Get the sustained/burst/peak power limits for the specific power domain. |
|
Set the sustained/burst/peak power limits for the specific power domain. |
|
Get the current energy threshold. |
|
Set the energy threshold. Event ZES_EVENT_TYPE_FLAG_ENERGY_THRESHOLD_CROSSED will be generated when the energy consumed since calling this function exceeds the specified threshold. |
The pseudo code below shows how to output information about each power domain on a device:
function ShowPowerDomains(zes_device_handle_t hSysmanDevice)
uint32_t numPowerDomains
if (zesDeviceEnumPowerDomains(hSysmanDevice, &numPowerDomains, NULL) == ZE_RESULT_SUCCESS)
zes_pwr_handle_t* phPower =
allocate_memory(numPowerDomains * sizeof(zes_pwr_handle_t))
if (zesDeviceEnumPowerDomains(hSysmanDevice, &numPowerDomains, phPower) == ZE_RESULT_SUCCESS)
for (pwrIndex = 0 .. numPowerDomains-1)
zes_power_properties_t props
if (zesPowerGetProperties(phPower[pwrIndex], &props) == ZE_RESULT_SUCCESS)
if (props.onSubdevice)
output("Sub-device %u power:n", props.subdeviceId)
output(" Can control: %s", props.canControl ? "yes" : "no")
call_function ShowPowerLimits(phPower[pwrIndex])
else
output("Total package power:n")
output(" Can control: %s", props.canControl ? "yes" : "no")
call_function ShowPowerLimits(phPower[pwrIndex])
free_memory(...)
}
function ShowPowerLimits(zes_pwr_handle_t hPower)
zes_power_sustained_limit_t sustainedLimits
zes_power_burst_limit_t burstLimits
zes_power_peak_limit_t peakLimits
if (zesPowerGetLimits(hPower, &sustainedLimits, &burstLimits, &peakLimits) == ZE_RESULT_SUCCESS)
output(" Power limitsn")
if (sustainedLimits.enabled)
output(" Sustained: %.3f W %.3f sec",
sustainedLimits.power / 1000,
sustainedLimits.interval / 1000)
else
output(" Sustained: Disabled")
if (burstLimits.enabled)
output(" Burst: %.3f", burstLimits.power / 1000)
else
output(" Burst: Disabled")
output(" Burst: %.3f", peakLimits.power / 1000)
The pseudo code shows how to output the average power. It assumes that the function is called regularly (say every 100ms).
function ShowAveragePower(zes_pwr_handle_t hPower, zes_power_energy_counter_t* pPrevEnergyCounter) zes_power_energy_counter_t newEnergyCounter; if (zesPowerGetEnergyCounter(hPower, &newEnergyCounter) == ZE_RESULT_SUCCESS) uint64_t deltaTime = newEnergyCounter.timestamp - pPrevEnergyCounter->timestamp; if (deltaTime) output(" Average power: %.3f W", (newEnergyCounter.energy - pPrevEnergyCounter->energy) / deltaTime); *pPrevEnergyCounter = newEnergyCounter;
Operations on frequency domains¶
The hardware manages frequencies to achieve a balance between best performance and power consumption. Most devices have one or more frequency domains.
The following functions are provided to manage the frequency domains on the device:
Function |
Description |
|---|---|
Enumerate all the frequency domains on the device and sub-devices. |
|
Find out which domain zes_freq_domain_t is controlled by this frequency and min/max hardware frequencies. |
|
Get an array of all available frequencies that can be requested on this domain. |
|
Get the current min/max frequency between which the hardware can operate for a frequency domain. |
|
Set the min/max frequency between which the hardware can operate for a frequency domain. |
|
Get the current frequency request, actual frequency, TDP frequency and throttle reasons for a frequency domain. |
|
Gets the amount of time a frequency domain has been throttled. |
It is only permitted to set the frequency range if the device property zes_freq_properties_t.canControl is true for the specific frequency domain.
By setting the min/max frequency range to the same value, software is effectively disabling the hardware-controlled frequency and getting a fixed stable frequency providing the Punit does not need to throttle due to excess power/heat.
Based on the power/thermal conditions, the frequency requested by software or the hardware may not be respected. This situation can be determined using the function zesFrequencyGetState() which will indicate the current frequency request, the actual (resolved) frequency and other frequency information that depends on the current conditions. If the actual frequency is below the requested frequency, zes_freq_state_t.throttleReasons will provide the reasons why the frequency is being limited by the Punit.
When a frequency domain starts being throttled, the event ZES_EVENT_TYPE_FLAG_FREQ_THROTTLED is triggered if this is supported (check zes_freq_properties_t.isThrottleEventSupported).
Frequency/Voltage overclocking¶
Overclocking involves modifying the voltage-frequency (V-F) curve to either achieve better performance by permitting the hardware to reach higher frequencies or better efficiency by lowering the voltage for the same frequency.
By default, the hardware imposes a factory-fused maximum frequency and a voltage-frequency curve. The voltage-frequency curve specifies how much voltage is needed to safely reach a given frequency without hitting overcurrent conditions. If the hardware detects overcurrent (IccMax), it will severely throttle frequencies in order to protect itself. Also, if the hardware detects that any part of the chip exceeds a maximum temperature limit (TjMax) it will also severely throttle frequencies.
To improve maximum performance, the following modifications can be made:
Increase the maximum frequency.
Increase the voltage to ensure stability at the higher frequency.
Increase the maximum current (IccMax).
Increase the maximum temperature (TjMax).
All these changes come with the risk of damage the device.
To improve efficiency for a given workload that is not excercising the full circuitry of the device, the following modifications can be made:
Decrease the voltage
Frequency overclocking is accomplished by calling zesFrequencyOcSetFrequencyTarget() with the desired Frequency Target and the Voltage setting by calling zesFrequencyOcSetVoltageTarget() with the new voltage and the voltrage offset. There are three modes that control the way voltage and frequency are handled when overclocking:
Overclock mode |
Description |
|---|---|
In this mode, a fixed user-supplied voltage VoltageTarget plus VoltageOffset is applied at all times, independent of the frequency request. This is not efficient but can improve stability by avoiding power-supply voltage changes as the frequency changes. |
|
In this mode, In this mode, the voltage/frequency curve can be extended with a new voltage/frequency point that will be interpolated. The existing voltage/frequency points can also be offset (up or down) by a fixed voltage. This mode disables FIXED and OVERRIDE modes. |
|
In this mode, In this mode, hardware will disable most frequency throttling and lock the frequency and voltage at the specified overclock values. This mode disables OVERRIDE and INTERPOLATIVE modes. This mode can damage the part, most of the protections are disabled on this mode. |
The following functions are provided to handle overclocking:
Function |
Description |
|---|---|
Determine the overclock capabilities of the device. |
|
Get current overclock target frequency set. |
|
Set the new overclock target frequency |
|
Get current overclock target voltage set. |
|
Set the new overclock target voltage and offset. |
|
Sets the desired overclock mode. |
|
Gets the current overclock mode. |
|
Get the maximum current limit in effect. |
|
Set a new maximum current limit. |
|
Get the maximum temperature limit in effect. |
|
Set a new maximum temperature limit. |
Overclocking can be turned off by calling zesFrequencyOcSetMode() with mode ZES_OC_MODE_OFF and by calling zesFrequencyOcGetIccMax() and zesFrequencyOcSetTjMax() with values of 0.0.
Scheduler operations¶
Scheduler components control how workloads are executed on accelerator engines and how to share the hardware resources when multiple workloads are submitted concurrently. This policy is referred to as a scheduler mode.
The available scheduler operating modes are given by the enum zes_sched_mode_t and summarized in the table below:
Scheduler mode |
Description |
|---|---|
This mode is optimized for multiple applications or contexts submitting work to the hardware. When higher priority work arrives, the scheduler attempts to pause the current executing work within some timeout interval, then submits the other work. It is possible to configure (zes_sched_timeout_properties_t) the watchdog timeout which controls the maximum time the scheduler will wait for a workload to complete a batch of work or yield to other applications before it is terminated. If the watchdog timeout is set to ZES_SCHED_WATCHDOG_DISABLE, the scheduler enforces no fairness. This means that if there is other work to execute, the scheduler will try to submit it but will not terminate an executing process that does not complete quickly. |
|
This mode is optimized to provide fair sharing of hardware execution time between multiple contexts submitting work to the hardware concurrently. It is possible to configure (zes_sched_timeslice_properties_t) the timeslice interval and the amount of time the scheduler will wait for work to yield to another application before it is terminated. |
|
This mode is optimized for single application/context use-cases. It permits a context to run indefinitely on the hardware without being preempted or terminated. All pending work for other contexts must wait until the running context completes with no further submitted work. |
|
This mode is optimized for application debug. It ensures that only one command queue can execute work on the hardware at a given time. Work is permitted to run as long as needed without enforcing any scheduler fairness policies. |
A device can have multiple scheduler components. Each scheduler component controls the workload execution behavior on one or more accelerator engines (zes_engine_type_flags_t). The following functions are available for changing the scheduler mode for each scheduler component:
Function |
Description |
|---|---|
Get handles to each scheduler component. |
|
Get properties of a scheduler component (sub-device, engines linked to this scheduler, supported scheduler modes. |
|
Get the current scheduler mode (timeout, timeslice, exclusive, single command queue) |
|
Get the settings for the timeout scheduler mode |
|
Get the settings for the timeslice scheduler mode |
|
Change to timeout scheduler mode and/or change properties |
|
Change to timeslice scheduler mode and/or change properties |
|
Change to exclusive scheduler mode and/or change properties |
|
Change to compute unit debug scheduler mode and/or change properties |
The pseudo code below shows how to stop the scheduler enforcing fairness while permitting other work to attempt to run:
function DisableSchedulerWatchdog(zes_device_handle_t hSysmanDevice)
uint32_t numSched
if ((zesDeviceEnumSchedulers(hSysmanDevice, &numSched, NULL) == ZE_RESULT_SUCCESS))
zes_sched_handle_t* pSchedHandles =
allocate_memory(numSched * sizeof(zes_sched_handle_t))
if (zesDeviceEnumSchedulers(hSysmanDevice, &numSched, pSchedHandles) == ZE_RESULT_SUCCESS)
for (index = 0 .. numSched-1)
ze_result_t res
zes_sched_mode_t currentMode
res = zesSchedulerGetCurrentMode(pSchedHandles[index], ¤tMode)
if (res == ZE_RESULT_SUCCESS)
ze_bool_t requireReload
zes_sched_timeout_properties_t props
props.watchdogTimeout = ZES_SCHED_WATCHDOG_DISABLE
res = zesSchedulerSetTimeoutMode(pSchedHandles[index], &props, &requireReload)
if (res == ZE_RESULT_SUCCESS)
if (requireReload)
output("WARNING: Reload the driver to complete desired configuration.")
else
output("Schedule mode changed successfully.")
else if(res == ZE_RESULT_ERROR_UNSUPPORTED_FEATURE)
output("ERROR: The timeout scheduler mode is not supported on this device.")
else if(res == ZE_RESULT_ERROR_INSUFFICIENT_PERMISSIONS)
output("ERROR: Don't have permissions to change the scheduler mode.")
else
output("ERROR: Problem calling the API to change the scheduler mode.")
else if(res == ZE_RESULT_ERROR_UNSUPPORTED_FEATURE)
output("ERROR: Scheduler modes are not supported on this device.")
else
output("ERROR: Problem calling the API.")
Tuning workload performance¶
While hardware attempts to balance system resources effectively, there are workloads that can benefit from external performance hints. For hardware where this is possible, the API exposes Performance Factors domains that can be used to provide these hints.
A Performance Factor is defined as a number between 0 and 100 that expresses a trade-off between the energy provided to the accelerator units and the energy provided to the supporting units. As an example, a compute heavy workload benefits from a higher distribution of energy at the computational units rather than for the memory controller. Alternatively, a memory bounded workload can benefit by trading off performance of the computational units for higher throughput in the memory controller. Generally the hardware will get this balance right, but the Performance Factor can be used to make the balance more aggressive. In the examples given, a Performance Factor of 100 would indicate that the workload is completely compute bounded and requires very little support from the memory controller. Alternatively, a Performance Factor of 0 would indicate that the workload is completely memory bounded and the performance of the memory controller needs to be increased.
Tuning for a workload can involve running the application repeatedly with different values of the Performance Factor from 0 to 100 and choosing the value that gives the best performance. The default value is 50. Alternatively, a more dynamic approach would involve monitoring the various utilization metrics of the accelerator to determine memory and compute bounded and moving the Performance Factor up and down in order to remove the bottleneck.
The API provides a way to enumerate the domains that can be controlled by a Performance Factor. A domain contains one or more accelerators whose performance will be affected by this setting. The API provides functions to change the Performance Factor for a domain.
Here is a summary of the available functions:
Function |
Description |
|---|---|
Enumerate the Performance Factor domains available on the hardware. |
|
Find out if the Performance Factor domain is located on a sub-device and which accelerators are affected by it. |
|
Read the current performance factor being used by the hardware for a domain. |
|
Change the Performance Factor of the hardware for a domain. |
Operations on engine groups¶
Accelerator resources (e.g. arrays of compute units or media decoders) are fed work by what are called engines. The API provides the ability to measuring the execution time (activity) of these engines. The type of engines is defined in the enum zes_engine_group_t.
Generally there is a one to one relationship between an engine and an underlying accelerator resource. For example, a single media decode engine submits work to a single media decoder hardware and no other engine can do so. Measuring the execution time (activity) of a single engine is equivalent to measuring the execution time of the underlying accelerator hardware.
There are also products where multiple engines submit work to the same underlying accelerator hardware. The hardware will execute the work from each engine concurrently. In these cases, the execution time of each individual engine will add up to more than the execution time of the underlying accelerator hardware since each engine is only receiving a portion of the accelerator hardware. In this case, the API also provides engine groups which will measure the total execution time at the level of the hardware accelerator rather than at the level of the individual engines. For example, the API may enumerate multiple engine groups of type ZES_ENGINE_GROUP_COMPUTE_SINGLE which will permit measuring the activity of each individual engine. However, to measure the overall activity of the shared compute resourses, the API will enumerate an engine group of type ZES_ENGINE_GROUP_COMPUTE_ALL.
By taking two snapshots of the activity counters, it is possible to calculate the average utilization of different parts of the device.
The following functions are provided:
Function |
Description |
|---|---|
Enumerate the engine groups that can be queried. |
|
Get the properties of an engine group. This will return the type of engine group (one of zes_engine_group_t) and on which sub-device the group is making measurements. |
|
Returns the activity counters for an engine group. |
Operations on standby domains¶
When a device is idle, it will enter a low-power state. Since exit from low-power states have associated latency, it can hurt performance. The hardware attempts to stike a balance between saving power when there are large idle times between workload submissions to the device and keeping the device awake when it determines that the idle time between submissions is short.
A device consists of one or more blocks that can autonomously power-gate into a standby state. The list of domains is given by zes_standby_type_t.
The following functions can be used to control how the hardware promotes to standby states:
Function |
Description |
|---|---|
Enumerate the standby domains. |
|
Get the properties of a standby domain. This will return the parts of the device that are affected by this domain (one of zes_engine_group_t) and on which sub-device the domain is located. |
|
Get the current promotion mode (one of zes_standby_promo_mode_t) for a standby domain. |
|
Set the promotion mode (one of zes_standby_promo_mode_t) for a standby domain. |
Operations on firmwares¶
The following functions are provided to manage firmwares on the device:
Function |
Description |
|---|---|
Enumerate all firmwares that can be managed on the device. |
|
Find out the name and version of a firmware. |
|
Flash a new firmware image. |
Querying Memory Modules¶
The API provides an enumeration of all device memory modules. For each memory module, the current and maximum bandwidth can be queried. The API also provides a health metric which can take one of the following values (zes_mem_health_t):
Memory health |
Description |
|---|---|
All memory channels are healthy. |
|
Excessive correctable errors have been detected on one or more channels. Device should be reset. |
|
Operating with reduced memory to cover banks with too many uncorrectable errors. |
|
Device should be replaced due to excessive uncorrectable errors. |
When the health state of a memory module changes, the event ZES_EVENT_TYPE_FLAG_MEM_HEALTH is triggered.
The following functions provide access to information about the device memory modules:
Function |
Description |
|---|---|
Enumerate the memory modules. |
|
Find out the type of memory and maximum physical memory of a module. |
|
Returns memory bandwidth counters for a module. |
|
Returns the currently health free memory and total physical memory for a memory module. |
Operations on Fabric ports¶
Fabric is the term given to describe high-speed interconnections between accelerator devices, primarily used to provide low latency fast access to remote device memory. Devices have one or more fabric ports that transmit and receive data over physical links. Links connect fabric ports, thus permitting data to travel between devices. Routing rules determine the flow of traffic through the fabric.
The figure below shows four devices, each with two fabric ports. Each port has a link that connects it to a port on another device. In this example, the devices are connected in a ring. Device A and D can access each other’s memory through either device B or device C depending on how the fabric routing rules are configured. If the connection between device B and D goes down, the routing rules can be modified such that device B and D can still access each other’s memory by going through two hops in the fabric (device A and C).
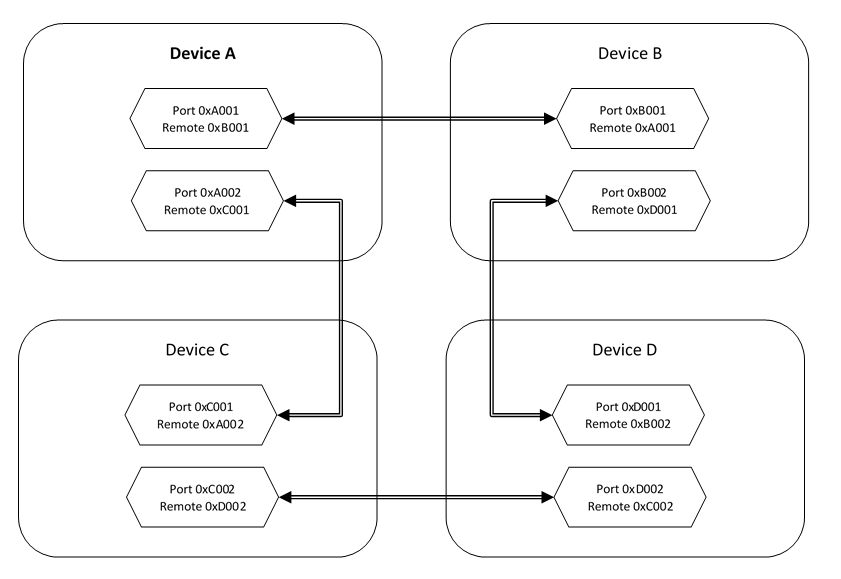
The API permits enumerating all the ports available on a device. Each port is uniquely identified within a system by the following information:
Fabric ID: Unique identifier for the fabric end-point
Attach ID: Unique identifier for the device attachment point
Port Number: The logical port number (this is typically marked somewhere on the physical device)
The API provides this information in the struct {t}_fabric_port_id_t. The identifiers are not universal - uniqueness is only guaranteed within a given system and provided the system configuration does not change.
When a fabric port is connected, the API provides the unique identifier for the remote fabric port. By enumerating all ports in a system and matching up the remote port identifies, an application can build up a topology map of connectivity.
For each port, the API permits querying its configuration (UP/DOWN) and its health which can take one of the following values:
Fabric port health |
Description |
|---|---|
The port is up and operating as expected. |
|
The port is up but has quality and/or bandwidth degradation. |
|
Port connection instabilities are preventing workloads making forward progress. |
|
The port is configured down. |
If the port is in a degraded state, the API provides additional information about the types of quality degradation that are being observed. If the port is in a red state, the API provides additional information about the causes of the instability.
When a port’s health state changes, the event ZES_EVENT_TYPE_FLAG_FABRIC_PORT_HEALTH is triggered.
The API provides the current transmit and receive bitrate of each port. It also permits measuring the receive and transmit bandwidth flowing through each port - these metrics include the protocol overhead in addition to traffic generated by the devices.
Since ports can pass data directly through to another port, the measured bandwidth at a port can be higher than the actual bandwidth generated by the accelerators directly connected by two ports. As such, bandwidth metrics at each port are more relevant for determining points of congestion in the fabric and less relevant for measuring the total bandwidth passing between two accelerators.
The following functions can be used to manage Fabric ports:
Function |
Description |
|---|---|
Enumerate all fabric ports on the device. |
|
Get static properties about the port (model, pord Id, max receive/transmit speed). |
|
Get details about the physical link connected to the port. |
|
Determine if the port is configured UP and if beaconing is on or off. |
|
Configure the port UP or DOWN and turn beaconing on or off. |
|
Determine the health of the port connection, reasons for link degradation or connection issues, current receive/transmit and port Id of the remote end-point. |
|
Get port receive/transmit counters along with current receive/transmit port speed. |
For devices with sub-devices, the fabric ports are usually located in the sub-device. Given a device handle, zesDeviceEnumFabricPorts() will include the ports on each sub-device. In this case, zes_fabric_port_properties_t.onSubdevice will be set to true and zes_fabric_port_properties_t.subdeviceId will give the subdevice ID where that port is located.
The pseudo-code below shows how to get the state of all fabric ports in the device and sub-devices:
void ShowFabricPorts(zes_device_handle_t hSysmanDevice)
uint32_t numPorts
if ((zesDeviceEnumFabricPorts(hSysmanDevice, &numPorts, NULL) == ZE_RESULT_SUCCESS))
zes_fabric_port_handle_t* phPorts =
allocate_memory(numPorts * sizeof(zes_fabric_port_handle_t))
if (zesDeviceEnumFabricPorts(hSysmanDevice, &numPorts, phPorts) == ZE_RESULT_SUCCESS)
for (index = 0 .. numPorts-1)
# Show information about a particular port
output(" Port %u:n", index)
call_function ShowFabricPortInfo(phPorts[index])
free_memory(...)
function ShowFabricPortInfo(zes_fabric_port_handle_t hPort)
zes_fabric_port_properties_t props
if (zesFabricPortGetProperties(hPort, &props) == ZE_RESULT_SUCCESS)
zes_fabric_port_state_t state
if (zesFabricPortGetState(hPort, &state) == ZE_RESULT_SUCCESS)
zes_fabric_link_type_t link
if (zesFabricPortGetLinkType(hPort, &link) == ZE_RESULT_SUCCESS)
zes_fabric_port_config_t config
if (zesFabricPortGetConfig(hPort, &config) == ZE_RESULT_SUCCESS)
output(" Model: %s", props.model)
if (props.onSubdevice)
output(" On sub-device: %u", props.subdeviceId)
if (config.enabled)
{
var status
output(" Config: UP")
switch (state.status)
case ZES_FABRIC_PORT_STATUS_HEALTHY:
status = "HEALTHY - The port is up and operating as expected"
case ZES_FABRIC_PORT_STATUS_DEGRADED:
status = "DEGRADED - The port is up but has quality and/or bandwidth degradation"
case ZES_FABRIC_PORT_STATUS_FAILED:
status = "FAILED - Port connection instabilities"
case ZES_FABRIC_PORT_STATUS_DISABLED:
status = "DISABLED - The port is configured down"
default:
status = "UNKNOWN"
output(" Status: %s", status)
output(" Link type: %s", link.desc)
output(
" Max speed (rx/tx): %llu/%llu bytes/sec",
props.maxRxSpeed.bitRate * props.maxRxSpeed.width / 8,
props.maxTxSpeed.bitRate * props.maxTxSpeed.width / 8)
output(
" Current speed (rx/tx): %llu/%llu bytes/sec",
state.rxSpeed.bitRate * state.rxSpeed.width / 8,
state.txSpeed.bitRate * state.txSpeed.width / 8)
else
output(" Config: DOWN")
Querying temperature¶
A device has multiple temperature sensors embedded at different locations. The following locations are supported:
Temperature sensor location |
Description |
|---|---|
Returns the maximum measured temperature across all sensors in the device. |
|
Returns the maximum measured temperature across all sensors in the GPU accelerator. |
|
Returns the maximum measured temperature across all sensors in the device memory. |
|
Returns the minimum measured temperature across all sensors in the device. |
|
Returns the minimum measured temperature across all sensors in the GPU accelerator. |
|
Returns the minimum measured temperature across all sensors in the device memory. |
For some sensors, it is possible to request that events be triggered when temperatures cross thresholds. This is accomplished using the function zesTemperatureGetConfig() and zesTemperatureSetConfig(). Support for specific events is accomplished by calling zesTemperatureGetProperties(). In general, temperature events are only supported on the temperature sensor of type ZES_TEMP_SENSORS_GLOBAL. The list below describes the list of temperature events:
Event |
Check support |
Description |
|---|---|---|
zes_temp_properties_t .isCriticalTempSupported |
The event is triggered when the temperature crosses into the critical zone where severe frequency throttling will be taking place. |
|
zes_temp_properties_t .isThreshold1Supported |
The event is triggered when the temperature crosses the custom threshold 1. Flags can be set to limit the trigger to when crossing from high to low or low to high. |
|
zes_temp_properties_t .isThreshold2Supported |
The event is triggered when the temperature crosses the custom threshold 2. Flags can be set to limit the trigger to when crossing from high to low or low to high. |
The following function can be used to manage temperature sensors:
Function |
Description |
|---|---|
Enumerate the temperature sensors on the device. |
|
Get static properties for a temperature sensor. In particular, this will indicate which parts of the device the sensor measures (one of zes_temp_sensors_t). |
|
Get information about the current temperature thresholds - enabled/threshold/processID. |
|
Set new temperature thresholds. Events will be triggered when the temperature crosses these thresholds. |
|
Read the temperature of a sensor. |
Operations on power supplies¶
The following functions can be used to access information about each power-supply on a device:
Function |
Description |
|---|---|
Enumerate the power supplies on the device that can be managed. |
|
Get static details about the power supply. |
|
Get information about the health (temperature, current, fan) of the power supply. |
Operations on fans¶
If zesDeviceEnumFans() returns one or more fan handles, it is possible to manage their speed. The hardware can be instructed to run the fan at a fixed speed (or 0 for silent operations) or to provide a table of temperature-speed points in which case the hardware will dynamically change the fan speed based on the current temperature of the chip. This configuration information is described in the structure zes_fan_config_t. When specifying speed, one can provide the value in revolutions per minute (ZES_FAN_SPEED_UNITS_RPM) or as a percentage of the maximum RPM (ZES_FAN_SPEED_UNITS_PERCENT).
The following functions are available:
Function |
Description |
|---|---|
Enumerate the fans on the device. |
|
Get the maximum RPM of the fan and the maximum number of points that can be specified in the temperature-speed table for a fan. |
|
Get the current configuration (speed) of a fan. |
|
Return fan control to factory default. |
|
Configure the fan to rotate at a fixed speed. |
|
Configure fan speed to depend on temperature. |
|
Get the current speed of a fan. |
The pseudo code below shows how to output the fan speed of all fans:
function ShowFans(zes_device_handle_t hSysmanDevice)
uint32_t numFans
if (zesDeviceEnumFans(hSysmanDevice, &numFans, NULL) == ZE_RESULT_SUCCESS)
zes_fan_handle_t* phFans =
allocate_memory(numFans * sizeof(zes_fan_handle_t))
if (zesDeviceEnumFans(hSysmanDevice, &numFans, phFans) == ZE_RESULT_SUCCESS)
output(" Fans")
for (fanIndex = 0 .. numFans-1)
int32_t speed
if (zesFanGetState(phFans[fanIndex], ZES_FAN_SPEED_UNITS_RPM, &speed)
== ZE_RESULT_SUCCESS)
output(" Fan %u: %d RPM", fanIndex, speed)
free_memory(...)
}
The next example shows how to set the fan speed for all fans to a fixed value in RPM, but only if control is permitted:
function SetFanSpeed(zes_device_handle_t hSysmanDevice, uint32_t SpeedRpm)
{
uint32_t numFans
if (zesDeviceEnumFans(hSysmanDevice, &numFans, NULL) == ZE_RESULT_SUCCESS)
zes_fan_handle_t* phFans =
allocate_memory(numFans * sizeof(zes_fan_handle_t))
if (zesDeviceEnumFans(hSysmanDevice, &numFans, phFans) == ZE_RESULT_SUCCESS)
zes_fan_speed_t speedRequest
speedRequest.speed = SpeedRpm
speedRequest.speedUnits = ZES_FAN_SPEED_UNITS_RPM
for (fanIndex = 0 .. numFans-1)
zes_fan_properties_t fanprops
if (zesFanGetProperties(phFans[fanIndex], &fanprops) == ZE_RESULT_SUCCESS)
if (fanprops.canControl)
zesFanSetFixedSpeedMode(phFans[fanIndex], &speedRequest)
else
output("ERROR: Can't control fan %u.n", fanIndex)
free_memory(...)
}
Operations on LEDs¶
If zesDeviceEnumLeds() returns one or more LED handles, it is possible to manage LEDs on the device. This includes turning them off/on and where the capability exists, changing their color in real-time.
The following functions are available:
Function |
Description |
|---|---|
Enumerate the LEDs on the device that can be managed. |
|
Find out if a LED supports color changes. |
|
Find out if a LED is currently off/on and the color where the capability is available. |
|
Turn a LED off/on and set the color where the capability is available. |
Querying RAS errors¶
RAS stands for Reliability, Availability, and Serviceability. It is a feature of certain devices that attempts to correct random bit errors and provide redundancy where permanent damage has occurred.
If a device supports RAS, it maintains counters for hardware and software errors. There are two types of errors and they are defined in zes_ras_error_type_t:
Error Type |
Description |
|---|---|
Hardware errors occurred which most likely resulted in loss of data or even a device hang. If an error results in device lockup, a warm boot is required before those errors will be reported. |
|
These are errors that were corrected by the hardware and did not cause data corruption. |
Software can use the function zesRasGetProperties() to find out if the device supports RAS and if it is enabled. This information is returned in the structure zes_ras_properties_t.
The function zesDeviceEnumRasErrorSets() enumerates the available sets of RAS errors. If no handles are returned, the device does not support RAS. A device without sub-devices will return one handle if RAS is supported. A device with sub-devices will return a handle for each sub-device.
To determine if errors have occurred, software uses the function zesRasGetState(). This will return the total number of errors of a given type (correctable/uncorrectable) that have occurred.
When calling zesRasGetState(), software can request that the error counters be cleared. When this is done, all counters of the specified type (correctable/uncorrectable) will be set to zero and any subsequent calls to this function will only show new errors that have occurred. If software intends to clear errors, it should be the only application doing so and it should store the counters in an appropriate database for historical analysis.
zesRasGetState() returns a breakdown of errors by category in the structure zes_ras_state_t. The table below describes the categories:
Error category |
||
|---|---|---|
Always zero. |
Number of accelerator engine resets attempted by the driver. |
|
Always zero. |
Number of hardware exceptions generated by the way workloads have programmed the hardware. |
|
Always zero. |
Number of low level driver communication errors have occurred. |
|
Number of errors that have occurred in the accelerator hardware that were corrected. |
Number of errors that have occurred in the accelerator hardware that were not corrected. These would have caused the hardware to hang and the driver to reset. |
|
Number of errors occurring in fixed-function accelerator hardware that were corrected. |
Number of errors occurring in the fixed-function accelerator hardware there could not be corrected. Typically these will result in a PCI bus reset and driver reset. |
|
Number of ECC correctable errors that have occurred in the on-chip caches (caches/register file/shared local memory). |
Number of ECC uncorrectable errors that have occurred in the on-chip caches (caches/register file/shared local memory). These would have caused the hardware to hang and the driver to reset. |
|
Number of ECC correctable errors that have occurred in the display. |
Number of ECC uncorrectable errors that have occurred in the display. |
Each RAS error type can trigger events when the error counters exceed thresholds. The events are listed in the table below. Software can use the functions zesRasGetConfig() and zesRasSetConfig() to get and set the thresholds for each error type. The default is for all thresholds to be 0 which means that no events are generated. Thresholds can be set on the total RAS error counter or on each of the detailed error counters.
RAS error Type |
Event |
|---|---|
The table below summaries all the RAS management functions:
Function |
Description |
|---|---|
Get handles to the available RAS error groups. |
|
Get properties about a RAS error group - type of RAS errors and if they are enabled. |
|
Get the current list of thresholds for each counter in the RAS group. RAS error events will be generated when the thresholds are exceeded. |
|
Set current list of thresholds for each counter in the RAS group. RAS error events will be generated when the thresholds are exceeded. |
|
Get the current state of the RAS error counters. The counters can also be cleared. |
The pseudo code below shows how to determine if RAS is supported and the current state of RAS errors:
void ShowRasErrors(zes_device_handle_t hSysmanDevice)
uint32_t numRasErrorSets
if ((zesDeviceEnumRasErrorSets(hSysmanDevice, &numRasErrorSets, NULL) == ZE_RESULT_SUCCESS))
zes_ras_handle_t* phRasErrorSets =
allocate_memory(numRasErrorSets * sizeof(zes_ras_handle_t))
if (zesDeviceEnumRasErrorSets(hSysmanDevice, &numRasErrorSets, phRasErrorSets) == ZE_RESULT_SUCCESS)
for (rasIndex = 0 .. numRasErrorSets)
zes_ras_properties_t props
if (zesRasGetProperties(phRasErrorSets[rasIndex], &props) == ZE_RESULT_SUCCESS)
var pErrorType
switch (props.type)
case ZES_RAS_ERROR_TYPE_CORRECTABLE:
pErrorType = "Correctable"
case ZES_RAS_ERROR_TYPE_UNCORRECTABLE:
pErrorType = "Uncorrectable"
default:
pErrorType = "Unknown"
output("RAS %s errors", pErrorType)
if (props.onSubdevice)
output(" On sub-device: %u", props.subdeviceId)
output(" RAS supported: %s", props.supported ? "yes" : "no")
output(" RAS enabled: %s", props.enabled ? "yes" : "no")
if (props.supported and props.enabled)
zes_ras_state_t errorDetails
if (zesRasGetState(phRasErrorSets[rasIndex], 1, &errorDetails)
== ZE_RESULT_SUCCESS)
uint64_t numErrors = 0
for (int i = 0; i < ZES_RAS_ERROR_CAT_MAX; i++)
numErrors += errorDetails.category[i];
output(" Number new errors: %llun", (long long unsigned int)numErrors);
if (numErrors)
call_function OutputRasDetails(&errorDetails)
free_memory(...)
function OutputRasDetails(zes_ras_state_t* pDetails)
output(" Number new resets: %llu", pDetails->category[ZES_RAS_ERROR_CAT_RESET])
output(" Number new programming errors: %llu", pDetails->category[ZES_RAS_ERROR_CAT_PROGRAMMING_ERRORS])
output(" Number new driver errors: %llu", pDetails->category[ZES_RAS_ERROR_CAT_DRIVER_ERRORS])
output(" Number new compute errors: %llu", pDetails->category[ZES_RAS_ERROR_CAT_COMPUTE_ERRORS])
output(" Number new non-compute errors: %llu", pDetails->category[ZES_RAS_ERROR_CAT_NON_COMPUTE_ERRORS])
output(" Number new cache errors: %llu", pDetails->category[ZES_RAS_ERROR_CAT_CACHE_ERRORS])
output(" Number new display errors: %llu", pDetails->category[ZES_RAS_ERROR_CAT_DISPLAY_ERRORS])
Performing Diagnostics¶
Diagnostics is the process of requesting that the hardware run self-checks and repairs.
WARNING: Performing diagnostics can destroy current device state. It is important that all workloads are stopped before initiating.
This is achieved using the function zesDiagnosticsRunTests(). On return from the function, software can use the diagnostics return code (zes_diag_result_t) to determine the new course of action:
ZES_DIAG_RESULT_NO_ERRORS - No errors found and workloads can resume submission to the hardware.
ZES_DIAG_RESULT_ABORT - Hardware had problems running diagnostic tests.
ZES_DIAG_RESULT_FAIL_CANT_REPAIR - Hardware had problems setting up repair. Card should be removed from the system.
ZES_DIAG_RESULT_REBOOT_FOR_REPAIR - Hardware has prepared for repair and requires a reboot after which time workloads can resume submission.
The function zesDeviceGetState() can be used to determine if the device has been repaired.
There are multiple diagnostic test suites that can be run. The function zesDeviceEnumDiagnosticTestSuites() will enumerate each available test suite and the function zesDiagnosticsGetProperties() can be used to determine the name of each test suite (zes_diag_properties_t.name).
Each test suite contains one or more diagnostic tests. On some systems, it is possible to run only a subset of the tests. Use the function zesDiagnosticsGetProperties() and check that zes_diag_properties_t.haveTests is true to determine if this feature is available. If it is, the function zesDiagnosticsGetTests() can be called to get the list of individual tests that can be run.
When running diagnostics for a test suite using zesDiagnosticsRunTests(), it is possible to specify the start and index of tests in the suite. Setting to ZES_DIAG_FIRST_TEST_INDEX and ZES_DIAG_LAST_TEST_INDEX will run all tests in the suite. If it is possible to run a subset of tests, specify the index of the start test and the end test - all tests that have an index in this range will be run.
The table below summaries all the diagnostic management functions:
Function |
Description |
|---|---|
Get handles to the available diagnostic test suites that can be run. |
|
Get information about a test suite - type, name, location and if individual tests can be run. |
|
Get list of individual diagnostic tests that can be run. |
|
Run either all or individual diagnostic tests. |
The pseudo code below shows how to discover all test suites and the tests in each:
function ListDiagnosticTests(zes_device_handle_t hSysmanDevice)
{
uint32_t numTestSuites
if ((zesDeviceEnumDiagnosticTestSuites(hSysmanDevice, &numTestSuites, NULL) == ZE_RESULT_SUCCESS))
zes_diag_handle_t* phTestSuites =
allocate_memory(numTestSuites * sizeof(zes_diag_handle_t))
if (zesDeviceEnumDiagnosticTestSuites(hSysmanDevice, &numTestSuites, phTestSuites) == ZE_RESULT_SUCCESS)
for (suiteIndex = 0 .. numTestSuites-1)
uint32_t numTests = 0
zes_diag_test_t* pTests
zes_diag_properties_t suiteProps
if (zesDiagnosticsGetProperties(phTestSuites[suiteIndex], &suiteProps) != ZE_RESULT_SUCCESS)
next_loop(suiteIndex)
output("Diagnostic test suite %s:", suiteProps.name)
if (!suiteProps.haveTests)
output(" There are no individual tests that can be selected.")
next_loop(suiteIndex)
if (zesDiagnosticsGetTests(phTestSuites[suiteIndex], &numTests, NULL) != ZE_RESULT_SUCCESS)
output(" Problem getting list of individual tests.")
next_loop(suiteIndex)
pTests = allocate_memory(numTests * sizeof(zes_diag_test_t*))
if (zesDiagnosticsGetTests(phTestSuites[suiteIndex], &numTests, pTests) != ZE_RESULT_SUCCESS)
output(" Problem getting list of individual tests.")
next_loop(suiteIndex)
for (i = 0 .. numTests-1)
output(" Test %u: %s", pTests[i].index, pTests[i].name)
free_memory(...)
Events¶
Events are a way to determine if changes have occurred on a device e.g. new RAS errors. An application registers the events that it wishes to receive notification about and then it queries to receive notifications. The query can request a blocking wait - this will put the calling application thread to sleep until new notifications are received.
For every device on which the application wants to receive events, it should perform the following actions:
Use zesDeviceEventRegister() to indicate which events it wants to listen to.
For each event, where appropriate, call the device component functions to set conditions that will trigger the event.
Finally, the application calls zesDriverEventListen() with a list of device handles that it wishes to listen for events on. A wait timeout is used to request non-blocking operations (timeout = 0) or blocking operations (timeout = UINT32_MAX) or to return after a specified amount of time even if no events have been received.
Note that calling zesDeviceEventRegister with no events (set argument events to “0”) will unregister all events that are being listened too. If the application has a thread blocked in the function zesDriverEventListen() and there are no more events to listen to, the function will unblock and return control to the application thread with an event count of 0.
When events are received, they are returned when the call to function zesDriverEventListen() completes. This will indicate which devices has generated events and the list of event types for each device. It is then up to the application to use the relevant device component functions to determine the state that has changed. For example, if the RAS error event has triggered for a device, then use the function zesRasGetState() to get the list of RAS error counters.
The list of events is given in the table below. For each event, the corresponding configuration and state functions are shown. Where a configuration function is not shown, the event is generated automatically; where a configuration function is shown, it must be called to enable the event and/or provide threshold conditions.
Event |
Trigger |
Configuration function |
State function |
|---|---|---|---|
Device is about to be reset by the driver |
|||
Device completed the reset by the driver |
|||
Device is about to enter a deep sleep state |
|||
Device is exiting a deep sleep state |
|||
|
Frequency starts being throttled |
||
Energy consumption threshold is reached |
|||
Critical temperature is reached |
|||
Temperature crosses threshold 1 |
|||
Temperature crosses threshold 2 |
|||
Health of device memory changes |
|||
Health of fabric ports change |
|||
RAS correctable errors cross thresholds |
|||
RAS uncorrectable errors cross thresholds |
|||
Driver has determined that an immediate reset is required |
The call to zesDriverEventListen() requires the driver handle and a list of device handles. THe device handles must have been enumerated from that driver, otherwise an error will be returned. If the application is managing devices from multiple drivers, it will need to call this function separately for each driver.
The table below summarizes all the event management functions:
Function |
Description |
|---|---|
Set the events that should be registered on a given event handle. |
|
Wait for events to arrive for a given list of devices. |
The pseudo code below shows how to configure all temperature sensors to trigger an event when the temperature exceeds a specified threshold or when the critical temperature is reached.
function WaitForExcessTemperatureEvent(zes_driver_handle_t hDriver, double tempLimit)
{
# This will contain the number of devices that we will listen for events from
var numListenDevices = 0
# Get list of all devices under this driver
uint32_t deviceCount = 0
zeDeviceGet(hDriver, &deviceCount, nullptr)
# Allocate memory for all device handles
ze_device_handle_t* phDevices =
allocate_memory(deviceCount * sizeof(ze_device_handle_t))
# Allocate memory for the devices from which we will listen to temperature events
zes_device_handle_t* phListenDevices =
allocate_memory(deviceCount * sizeof(zes_device_handle_t))
# Allocate memory for the events that have been received from each device in phListenDevices
zes_event_type_flags_t* pDeviceEvents =
allocate_memory(deviceCount * sizeof(zes_event_type_flags_t))
# Allocate memory so that we can map device handle in phListenDevices to the device index
uint32_t* pListenDeviceIndex = allocate_memory(deviceCount * sizeof(uint32_t))
# Get all device handles
zeDeviceGet(hDriver, &deviceCount, phDevices)
for(devIndex = 0 .. deviceCount-1)
# Get Sysman handle for the device
zes_device_handle_t hSysmanDevice = (zes_device_handle_t)phDevices[devIndex]
# Get handles to all temperature sensors
uint32_t numTempSensors = 0
if (zesDeviceEnumTemperatureSensors(hSysmanDevice, &numTempSensors, NULL) != ZE_RESULT_SUCCESS)
next_loop(devIndex)
zes_temp_handle_t* allTempSensors
allocate_memory(deviceCount * sizeof(zes_temp_handle_t))
if (zesDeviceEnumTemperatureSensors(hSysmanDevice, &numTempSensors, allTempSensors) == ZE_RESULT_SUCCESS)
# Configure each temperature sensor to trigger a critical event and a threshold1 event
var numConfiguredTempSensors = 0
for (tempIndex = 0 .. numTempSensors-1)
if (zesTemperatureGetConfig(allTempSensors[tempIndex], &config) != ZE_RESULT_SUCCESS)
next_loop(tempIndex)
zes_temp_config_t config
config.enableCritical = true
config.threshold1.enableHighToLow = false
config.threshold1.enableLowToHigh = true
config.threshold1.threshold = tempLimit
config.threshold2.enableHighToLow = false
config.threshold2.enableLowToHigh = false
if (zesTemperatureSetConfig(allTempSensors[tempIndex], &config) == ZE_RESULT_SUCCESS)
numConfiguredTempSensors++
# If we configured any sensors to generate events, we can now register to receive on this device
if (numConfiguredTempSensors)
if (zesDeviceEventRegister(phDevices[devIndex],
ZES_EVENT_TYPE_FLAG_TEMP_CRITICAL | ZES_EVENT_TYPE_FLAG_TEMP_THRESHOLD1)
== ZE_RESULT_SUCCESS)
phListenDevices[numListenDevices] = hSysmanDevice
pListenDeviceIndex[numListenDevices] = devIndex
numListenDevices++
# If we registered to receive events on any devices, start listening now
if (numListenDevices)
# Block until we receive events
uint32_t numEvents
if (zesDriverEventListen(hDriver, UINT32_MAX, numListenDevices, phListenDevices, &numEvents, pDeviceEvents)
== ZE_RESULT_SUCCESS)
if (numEvents)
for (evtIndex .. numListenDevices)
if (pDeviceEvents[evtIndex] & ZES_EVENT_TYPE_FLAG_TEMP_CRITICAL)
output("Device %u: Went above the critical temperature.",
pListenDeviceIndex[evtIndex])
else if (pDeviceEvents[evtIndex] & ZES_EVENT_TYPE_FLAG_TEMP_THRESHOLD1)
output("Device %u: Went above the temperature threshold %f.",
pListenDeviceIndex[evtIndex], tempLimit)
free_memory(...)
Security¶
Linux¶
The default security provided by the accelerator driver is to permit querying and controlling of system resources to the UNIX user root, querying only for users that are members of the UNIX group root and no access to any other user. Some queries are permitted from any user (e.g. requesting current frequency, checking standby state).
It is the responsibility of the Linux distribution or the systems administrator to relax or tighten these permissions. This is typically done by adding udev daemon rules. For example, many distributions of Linux have the following rule:
root video /dev/dri/card0
This will permit all users in the UNIX group video to query information about system resources. In order to open up control access to users of the video group, udev rules need to be added for each relevant control. For example, to permit someone in the video group to disable standby, the following udev daemon rule would be needed:
chmod g+w /sys/class/drm/card0/rc6_enable
The full list of sysfs files used by the API are described in the table below. For each file, the list of affected API functions is given.
sysfs file |
Description |
Functions |
|---|---|---|
/sys/class/drm/card0/ rc6_enable |
Used to enable/disable standby. |
zesDeviceEnumStandbyDomains() zesStandbyGetProperties() zesStandbyGetMode() zesStandbySetMode() |
TBD |
In development |
TBD |
Windows¶
The Windows driver will only permit telemetry requests coming from users with administrator permissions. It will only permit controls for system services with LocalServiceSid permissions.
Virtualization¶
In virtualization environments, only the host is permitted to access any features of the API. Attempts to use the API in virtual machines will fail.